Zhanna Kaufman
PhD Student
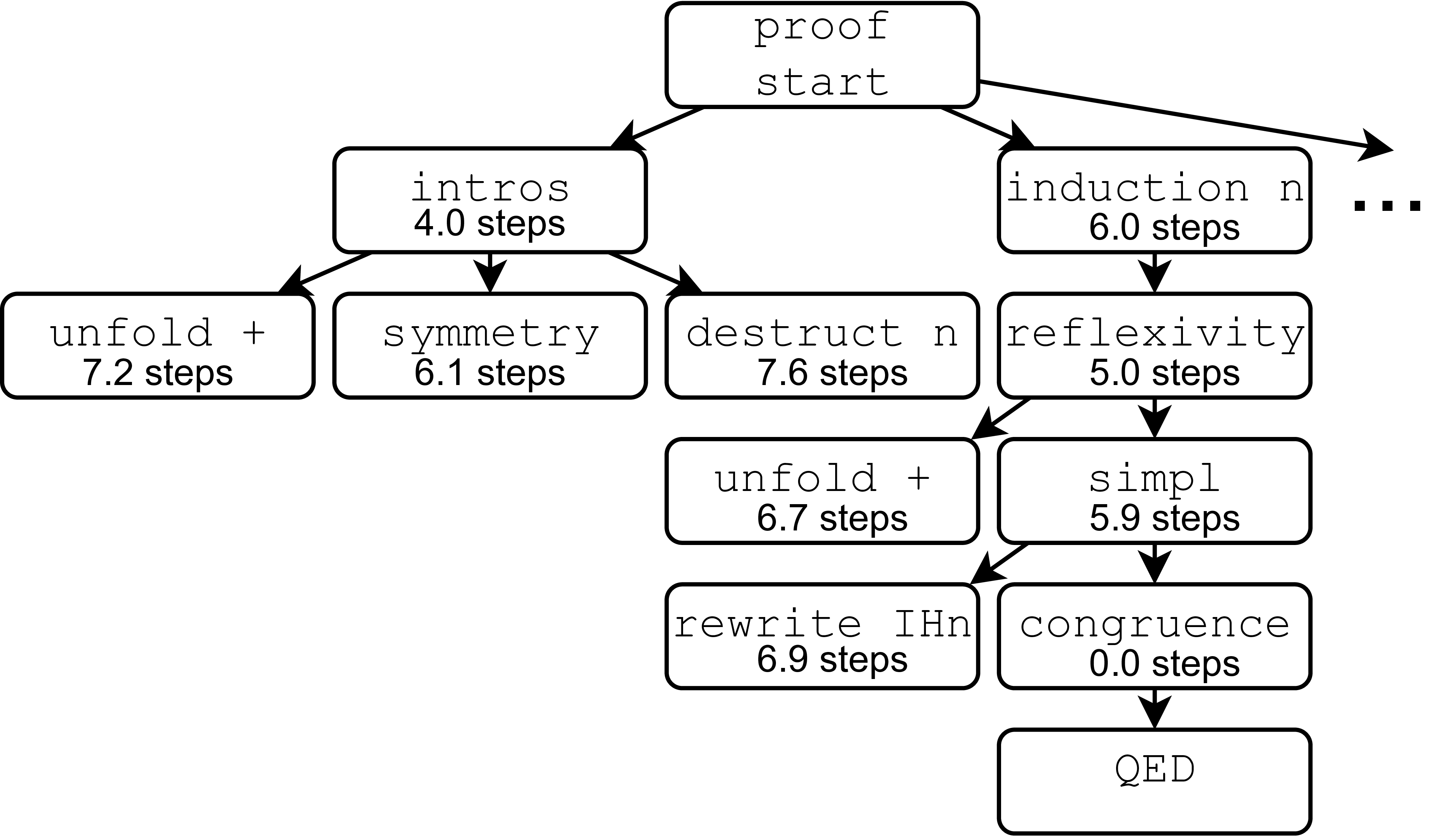
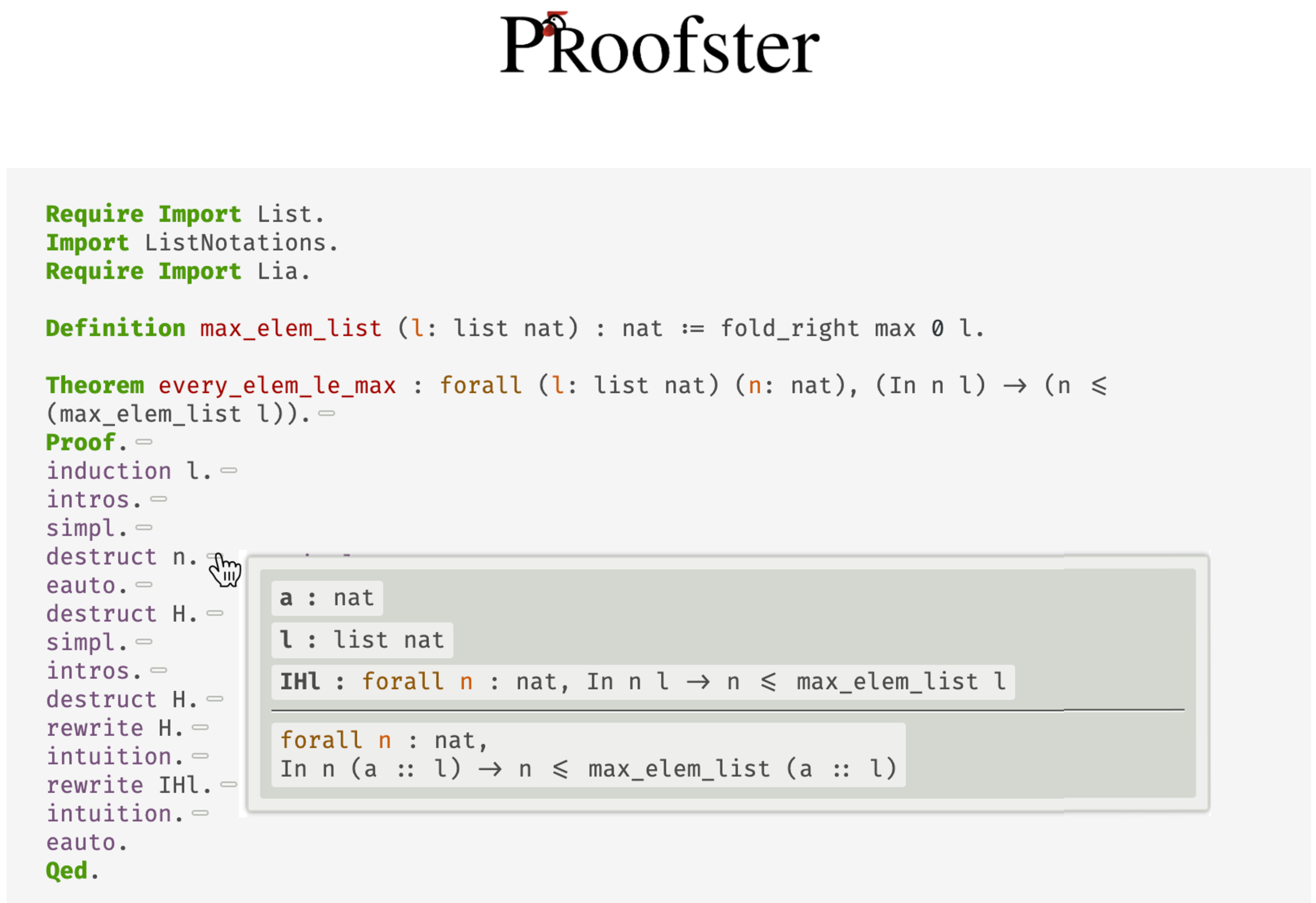
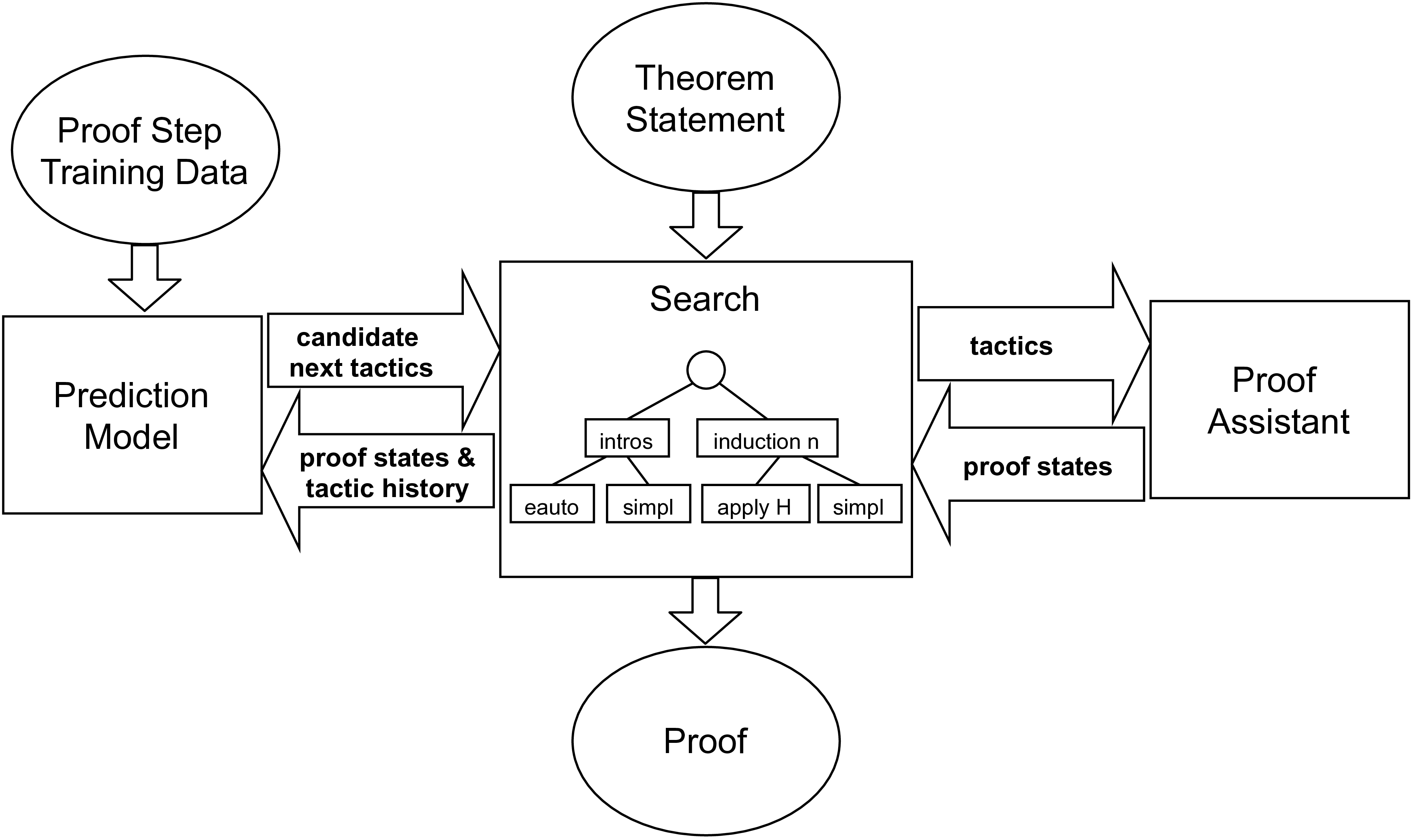
The second area of my research supports the creation of trustworthy software with ML assistance. Specifically, we use machine learning in combination with theorem prover tools such as Coq to automate proof synthesis. The aim of this work is to use automation to make proving code correctness accessible to large projects and to developers without expertise in formal verification.
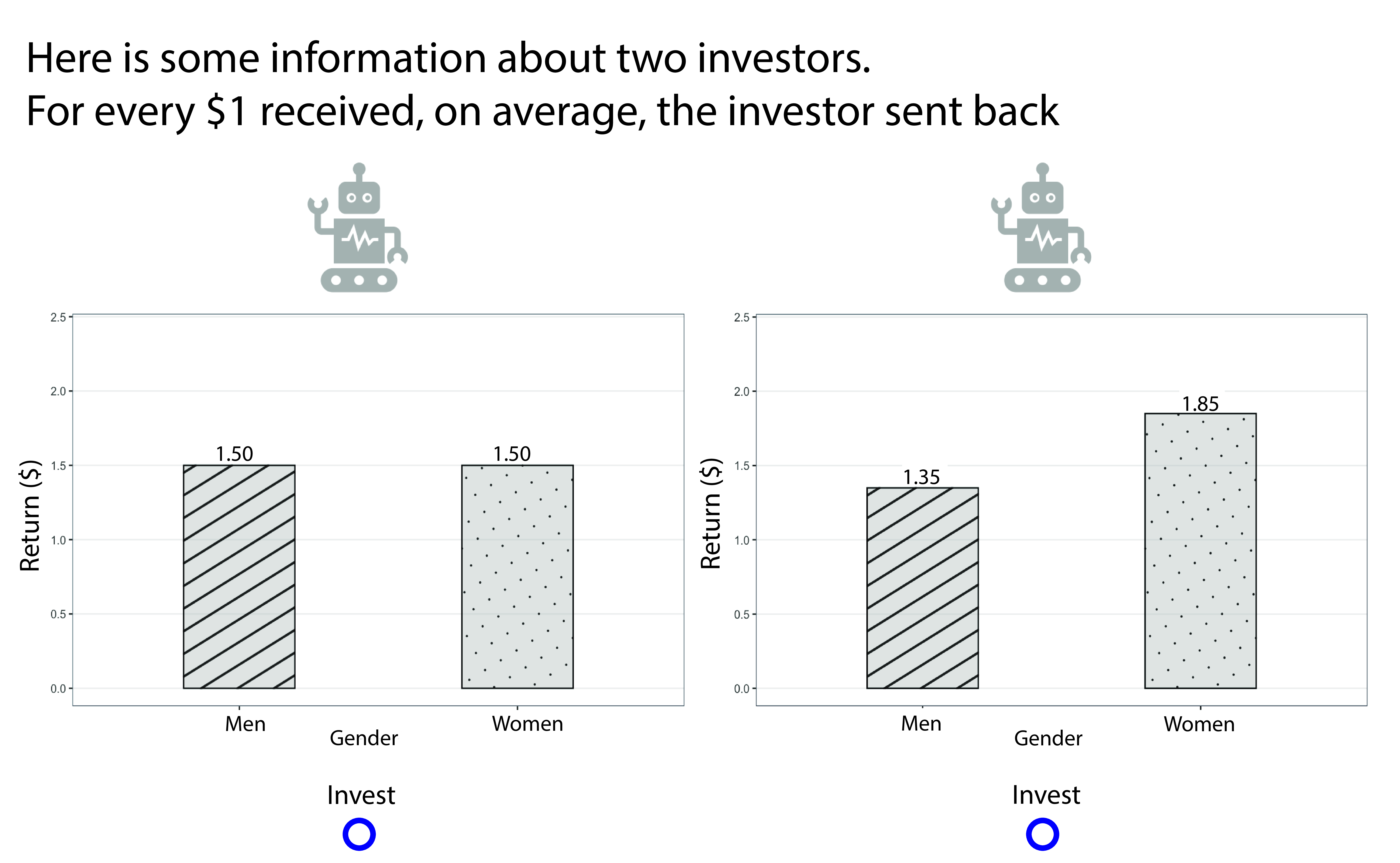
More recently, I have begun work on understanding human robustness to incorrect natural language descriptions of formally specified postconditions. The goal of this work is to help developers calibtrate their dependence on ML assistance when writing tests for code, and more effectively use code assistance to create trustworthy software.
Before coming to UMASS, I worked for six years in industry as a Cyber Research and Innovation Engineer. I received my Bachelor's in Electrical Engineering from Boston University in 2015 and my MS in Computer Science from Worcester Polytechnic Institute in 2018.
My latest completed projects